do not dot the ı, even in pixels

I once wrote about the dotless ı in my name. In Turkish, Fırat isn’t Firat. My name comes from the river Euphrates, which we call Fırat in Turkish, and that dotless ı has its own sound. The capitalization rule is pretty straightforward: ı becomes I, and i becomes İ. Everyone keeps their dots, or their lack of one.
The old bug lived in strings. A form, a font, an encoding path, or a careless toUpperCase() call would turn my name into something close enough for a machine and wrong enough for me. I wrote do not dot the ı for friends who were curious about that letter. It became one of my favorite essays to point people to.
That older essay ended with a small peace treaty. It’s alright if someone types my name with a dot. It’s alright if they pronounce it a little differently than my parents do. My unreasonable wish was for the machines to learn the right version anyway, so none of us had to keep negotiating with autocomplete.
Then image models started drawing signs.
So I built Dottıng.
My hypothesis for Dottıng was simple: if text-to-image models are now good at visible text, we would not see the false dots on the dotless ı. Compare many models, prompts, words, and seeds; look closely at the outputs; and see whether this Turkish letter is still a useful benchmark.

A benchmark one dot wide
Dottıng asks image models to write Turkish words and checks whether the letters survive. The headline case is the dotless ı, but the test also includes ç, ğ, ö, ş, and ü, because Turkish travels as a system of small marks that all need to arrive.
The initial release in June 2026 lists 8,400 combinations: 40 models, 15 Turkish words and phrases, 7 prompt contexts, and 2 seeds. I manually classified 1,055 of them, then used AI judges to scan the rest.
The word list had three jobs: dotless ı traps, companion marks like ç, ğ, and ş, and ö/ü controls because German shares them. The memorable targets were kız, ışık, adâbımuâşeret, an Ottoman mouthful of â, ı, and ş, and Yaşamak bir ağaç gibi tek ve hür, the Nazım Hikmet line where ç, ğ, ş, and ü all have to survive. I was genuinely impressed by how often newer models got close.
The labels are intentionally visual: correct, dotted, substituted, mangled, offtask. The label belongs to the image, not to the model’s intention. If the prompt asked for Fırat and the image says Firat, the visible result is dotted. The model doesn’t get partial credit for meaning well.
This is not a universal ranking of image quality or Turkish support. It is a focused glyph test: can a model put the right letters into pixels under these prompts?
The eye stayed in the loop
The AI judges started as a second question. Since I had manually classified 1,055 images, I could also ask how well LLM-as-a-judge aligned with my own eye.
That turned the employment of judges into one of the research findings.
I expected the judges to save time. I didn’t expect their mistakes to echo the original bug so neatly.
A vision model can look at an image, recognize the intended word, and quietly normalize the visible mistake away. This seems to be the original bug, moved one layer higher: the system preserves the idea of the word while losing the letter.
Gemini 3.5 Flash was the strongest full-corpus scout in this run. Claude Sonnet 4.6 gave a near-full second pass, and smaller judge panels helped compare failure modes. Gemini matched human classifications on the overlap about 81% of the time and caught about nine in ten wrongly dotted ı cases, making it useful for triage.
Human labels stayed central because this benchmark is about what is visible. The eye has to remain in the loop when the bug is one dot wide.

Prompting moved the mistake around
I also tested prompt contexts: plain signs, serif posters, handwritten notes, LED dot-matrix displays, Turkish-language instructions, and explicit glyph coaching.
Coaching helped in places, but it didn’t solve the problem. Turkish prompts reduced some wrong dots and made some images less readable. Sometimes the model stopped writing the word and drew the meaning instead. Ask for kız (means “girl” in English), and you might get a girl standing on a beach. Beautiful, but off-task. On the site I called this “meaning instead of text.”
That was useful to see. Telling a model not to dot the ı isn’t the same thing as giving it a stable representation of Turkish. Sometimes the prompt doesn’t remove the error. It moves it somewhere else.
Context changes the failure mode more than it cures it.
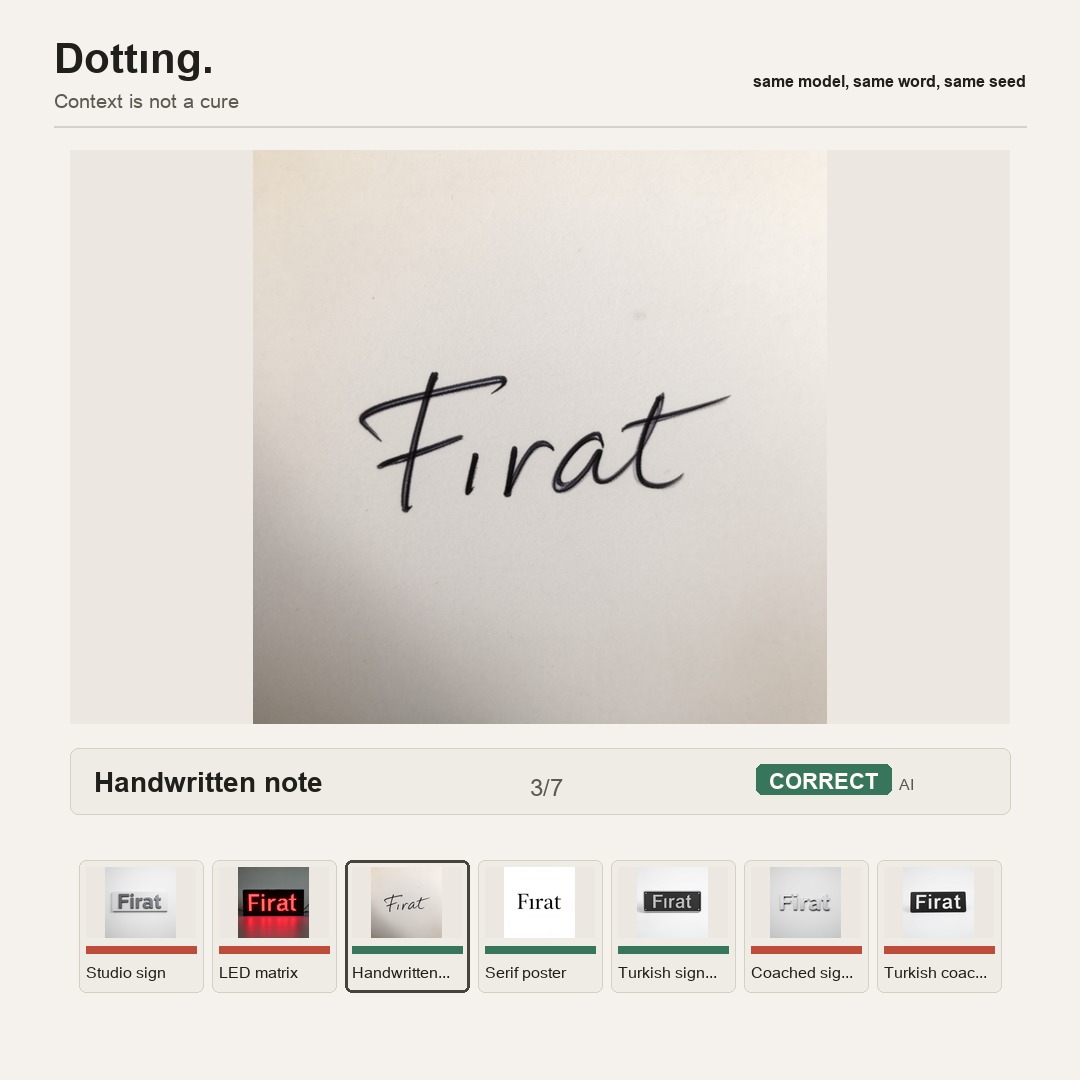
The dot was small; the tech stack was not
I thought the hard part would be generating the images. It wasn’t. The project turned into a Python pipeline, a Runware operations test, a classification tool, an AI judge study, a WordPress site, a Turkish localization pass, social preview assets, and a reusable data package. Apparently this is what I do when a dot annoys me.
The AI model costs totaled up to $535. Image generation was the expensive part, followed by AI evaluation. Read back was cheap.
The raw corpus was about 14GB of PNGs. That was fine for research but too large for a public site. The release package uses optimized WebP images and route-scoped JSON payloads, turning the lab results into something WordPress could serve as an essay, gallery, and leaderboard.
I built the site mostly by writing plain-English instructions: what the page should say, what the specimens should show, what the leaderboard should make visible. I wasn’t touching the code or WordPress directly. Codex and Claude Code, two AI coding agents, used the WordPress Studio CLI in the background to change the theme, wire in the data, push previews, sync the site, and run launch checks.
One alternative solution here would have been a static site or a Python notebook with images in folders. But I wanted the public object to feel like a small website: essay first, specimens close by, leaderboard and methodology pages providing research details on demand.
Studio gave the agents a shared language for local WordPress work, and preview sites gave us something real to inspect. Studio got this weird, data-heavy research project much further than I expected, and made a polished WordPress site possible.
The site had to be a story before it became a table, so it opens with specimens and teaches the eye before showing the leaderboard. You have to see the dot before the stats mean anything.
The reusable dataset lives on Hugging Face as a Dataset and a static Space, for anyone who wants to inspect the rows instead of only the story, or run the benchmark with different setups.
A bug you can watch being fixed
The bug isn’t gone. It is now visible enough to measure, and you can watch it shrink across model generations.
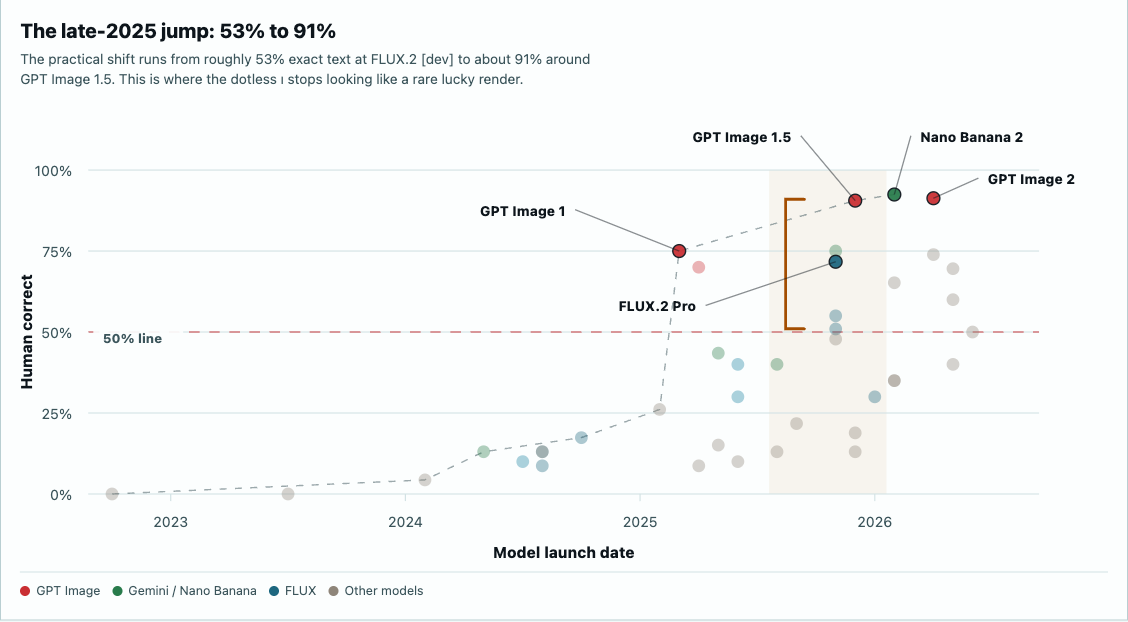
The late-2025 jump: 53% to 91%
The practical shift runs from roughly 53% exact text at FLUX.2 [dev] to about 91% around GPT Image 1.5. This is where the dotless ı stops looking like a rare lucky render.
This isn’t only about Turkish or image models. Every system has places where a tiny mark carries more meaning than it seems to. A good benchmark gives you a place to look.
Early models often turn text into texture. Later models make images that look typographic from far away and collapse under close reading. Newer models are much better. The best ones keep the dotless ı most of the time, then still fail just often enough to remind you why the test exists.
My old wish was that machines would autocomplete Fırat correctly. This new wish is more concrete: publish tests like this, give the machines better Turkish to learn from, and keep asking for the dot to land exactly where it belongs, which on this ı is nowhere.