Building a Claude Code Skill Over 50+ Iterations
Hello there!
I built a Claude Code skill that analyzes A/B experiments. It pulls data from Trino, runs Bayesian statistics, generates a marimo notebook, and exports an HTML report. A teammate can kick off a full analysis with one command instead of manually going through 2800 lines of notebook.
A skill is a folder that teaches Claude Code how to do a specific task. A folder full of instructions, workflow, templates, conventions; all in one place. The skill enables automating A/B experiment analysis by Claude in 10-30 minutes, instead of the previously manual work of a couple of hours.
This post is about the fifty-plus iterations it took to get there.
Templates prevent the hallucinations
My first version asked Claude to compute and interpret statistics in the same step. It mostly worked. When it failed, I couldn’t tell whether a number was wrong or a sentence was wrong.
I split the work into two passes. Pass #1 runs the statistics deterministically and writes results to JSON. Pass #2 reads those JSONs and asks Claude to generate commentary grounded in the numbers already computed. Pass #2 is also where Claude catches issues from the first pass: missing data, failed queries, anomalies.
The same logic applied to SQL. Early on, the agent generated queries on the fly, guessing column names like attribution_window_start when the real one was attribution_window_start_ts.
The fix is obvious in retrospect: stop letting it write SQL on the fly. I pre-composed each query as a .sql template, stored it in the skill, and added one line to SKILL.md: “Run SQL templates verbatim.” Load the pre-composed SQL file, substitute placeholders, execute the query.
It didn’t seem obvious in the beginning; I thought the model was smart enough to figure out the schema from context and free form exploration (probably it could, given more time and iterations). It took a few rounds of the same failure to accept that smart wasn’t the issue. Asking AI to reason about schema, smart-guessing, is still guessing. When I handed it precomposed queries with placeholders to update, errors dropped to near zero.
I did the same for the notebook. The marimo notebook is a chain of Python cells. Instead of letting Claude decide the visualizations to generate or how to connect data points, I gave it a notebook template with placeholders: __EXPERIMENT_ID__, __METRIC_ASSIGNMENT_ID__, __TREATMENT_VARIATIONS_JSON__. Claude substitutes the values and runs the code. It doesn’t generate all of the code.
Some inputs come from the user. The skill uses AskUserQuestion to collect preferences: attribution window, spammer handling, viewport segmentation. Those answers become template variables.
The pattern: don’t ask the model to reason about structure. Give it the structure. Specify the data model. Then, let it fill in the blanks.
Throw compute at the problem
All of these insights came from iteration. Fifty-plus rounds.
Round 1 produced a working notebook. Round 5 added sample ratio mismatch and data validation diagnostics. Round 10 introduced an AI self-review pass. Round 15 added the forest-plot credible-interval chart. Each pass was small, but they stacked up.
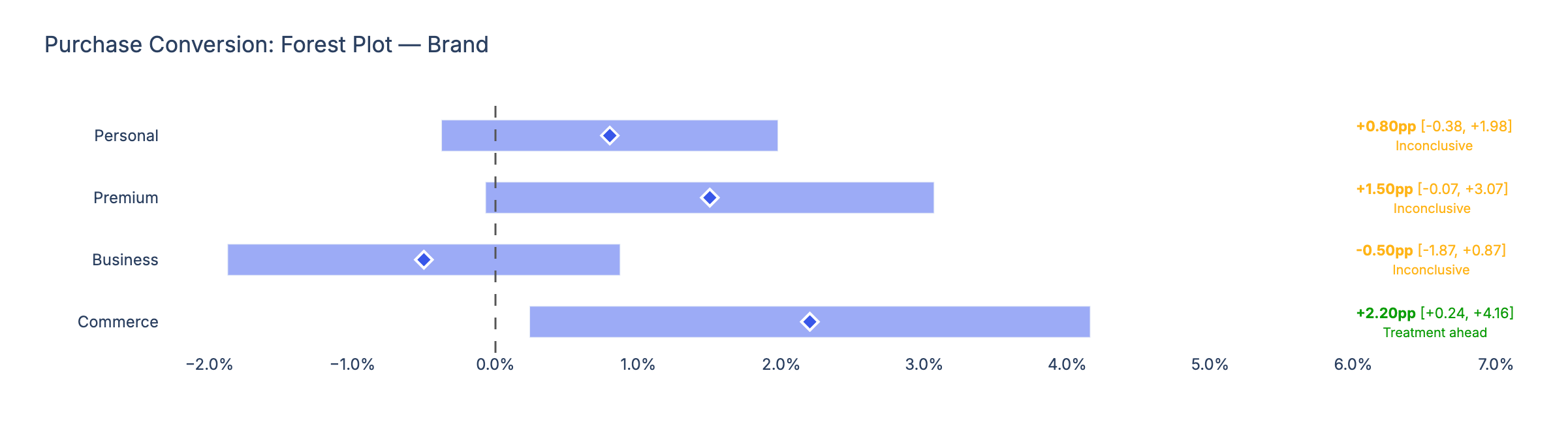
The self-review pass was the surprise. After Claude generates its first draft, I ask it review the draft against a five-item checklist: Does every number trace back to the JSON? Does every claim include raw numbers retrieved earlier? Does the prose match the summary-table verdict? The model catches its own mistakes, regenerates once if needed, then injects the final commentary into the notebook. More computation on the same problem increases quality visibly.
Partway through, I started asking the model to review its own code: three parallel agents checking for reuse, quality, and efficiency. They found a duplicated constant, a double DataFrame merge that should have been a left join, redundant function calls. Not every finding was worth fixing. The adversarial review pattern works because we throw more compute at the problem. Run the probabilistic check, fix the issue, run the probabilistic check again, find a new issue to fix.
I kept going until the issues that surfaced were smaller than the effort to fix them. The skill never reached zero findings. Even on the last prompt before merging code, I was still fixing a Trino query edge case and reordering the user prompts. But the added value shrank from “the numbers don’t add up” to “swap the order of two questions.” The diminishing returns here is the signal to let go and merge.
The model can only catch what it knows to look for. Reviews from Isa and Aaron, who have done hundreds of experiment analyses, caught things the agent missed: better visualization choices, a cleaner presentation, and decisions about what belongs in the skill scope. Human reviewers care about things the model does not care to check.
SKILL.md is a log of failures
SKILL.md started as a simple workflow outline. Four steps. Working code.
Now it’s a log of everything that has gone wrong.
Every time the agent did something I didn’t want, I added a line. Guessed attribution_window_start when the column was attribution_window_start_ts. Used matplotlib instead of Plotly. Generated five separate notebooks for five treatments instead of one. Assumed environment variables from .zshrc when the Bash tool doesn’t source that file.
At the end, the file has critical rules, a six-step workflow, an anti-patterns table, and a troubleshooting section. Each entry exists because something broke without it.
Claude can work through vague instructions. It can figure things out. Showing it the exact failure modes upfront makes every future run faster. Fewer wrong turns.
The joy was in the abstraction
I spent over fifty iterations on this skill and many more hours than it would have taken to do the analysis manually.
I could have done the analysis. One experiment, one notebook, move on. Instead, I went up an abstraction level. I solved the automation problem, which meant solving it once for every future experiment.
Software is getting easier to make. Most of what gets made will probably be fine. Functional, but forgettable. Made quickly without much thought. There’s pressure to move faster, automate more, have your agents do it for you.
I don’t think AI changes what craft means. It’s just one more tool available to people who take the time to make useful things. Like any tool, it should be used with intention.
Fifty iterations was me applying intention. Pouring time into something until it felt right. Building something that works without me is more fun than doing the work myself.